prometheus高可用
一、应用场景
HCI超融合的监控,我们的应用程序将会和主机一起打包销售,给到客户的时候启动主机,这个主机有可能是1台也有可能是3台。那么主机启动之后,监控服务随之启动,业务会暴露指标给prometheus采集,这里的prometheus如果有1台主机那么就只有1个监控服务,如果有3台主机那么就会有3个监控服务,这3台机器上面的3个prometheus的实例各自的存储是独立的。
二、需求
- prometheus任何一台宕机,监控情况正常;
- prometheus独立于业务之外,监控不会影响业务,也就是在内存、磁盘等占用不会影响业务正常运行;
三、目标
- prometheus的高可用方案(数据同步、配置热重载、主从选举);
- 限制prometheus的资源消耗;
四、数据同步方案
- 多个Prometheus采集完全一样的数据,外边挂负载均衡用于查询监控数据
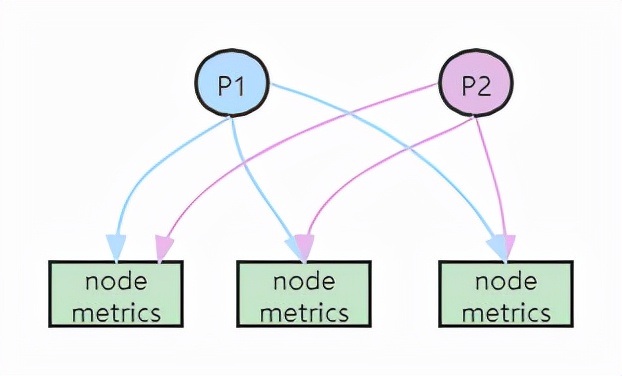
优点:
- 配置简单
缺点:
数据一致性取决于数据拉取频率,频率不高情况下,数据一致性较差;
数据拉取频率高的情况下,对于业务的指标采集接口增加了网络IO压力,并且随着主机增多,压力加大;
单机存储不适用于海量数据
多个prometheus将数据写入远程
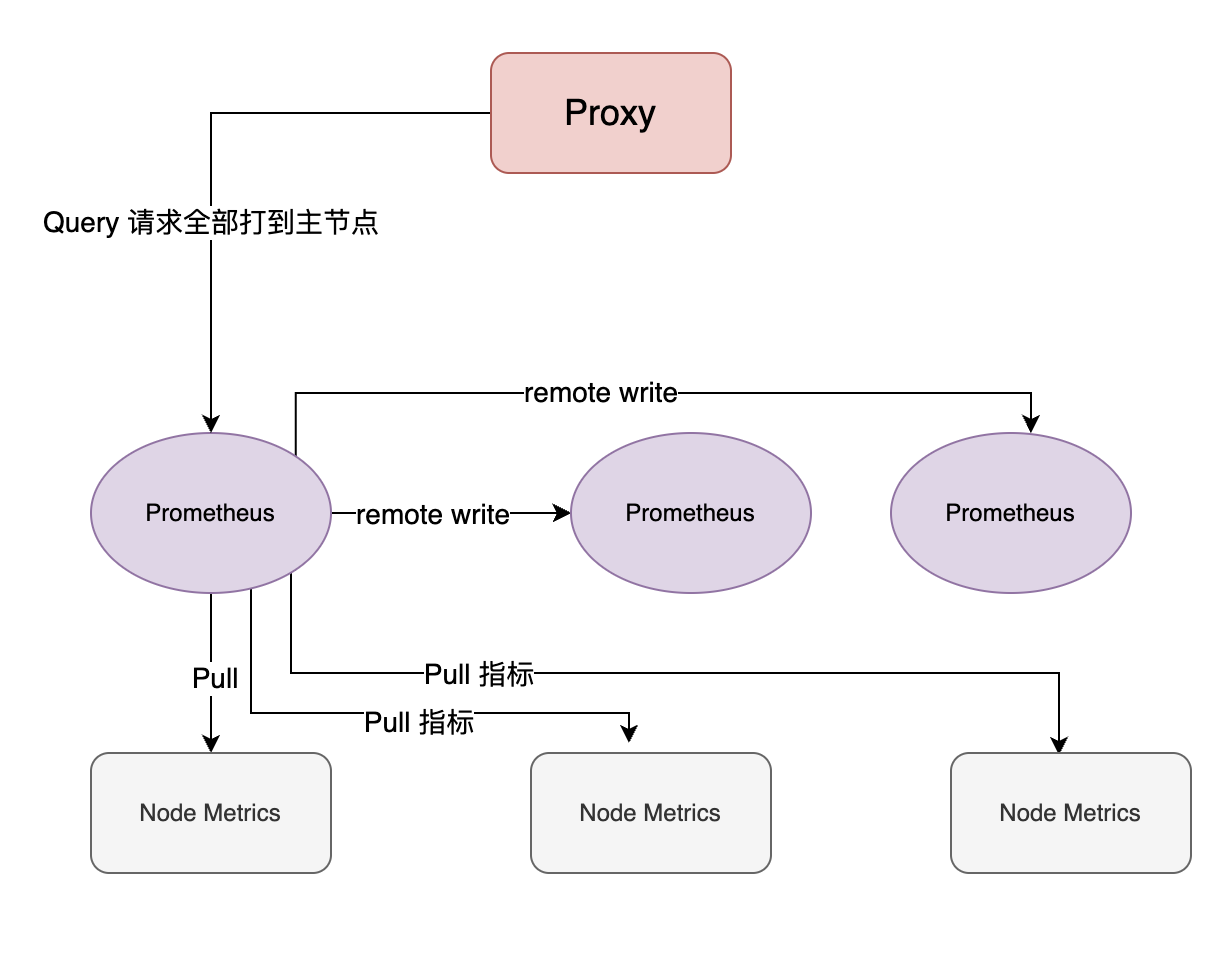
Prometheus的远程存储接口可以支持多种实现比如 Elasticsearch或者prometheus自身也提供了write接口;Prometheus 的 remote write 当 Prometheus 从目标上 pull 数据时,它会立即将这些数据写入本地存储,然后再将这些数据发送到远程写入端点。如果在此过程中发生错误,远程写入可能会失败,但不会导致数据丢失,因为数据已经写入了本地存储。 如果远程写入失败,会自动重试多次(次数可以配置)发送数据;
- 优点:a.如果外挂存储引擎可以解决单机数据存储局限的问题;b.配置简单;
- 缺点:a.如果使用外部存储殷勤,需要额外部署一个远端数据存储服务;b.通过remote write失败会进行重试,这个重试次数和间隔不太好确定,不同的负载、业务需求都会不一样;
- 基于prometheus的federation联邦机制同步数据,做一主多从
prometheus的端点/federate可以用于指标数据拉取,但是仅支持即时查询 Instant Query 返回的内容叫做即时向量 Instant Vector;同步时候仅仅可以获取当前某一个指标的最近的值;当新纳入一个节点时候,从prometheus从主prometheus拉取指标时候,只能拉取最新的指标,历史的指标不能拉取;所以新纳入一个节点,启动之前需要将主节点的prometheus的data数据目录同步过来,比如本地数据存储默认是 /data 目录。纳入新节点,开始同步文件到同步完成,最后启动从节点,这一段时间,主节点是仍然在工作的,这一段时间的指标,在从节点是不会被拉取的,会丢失。
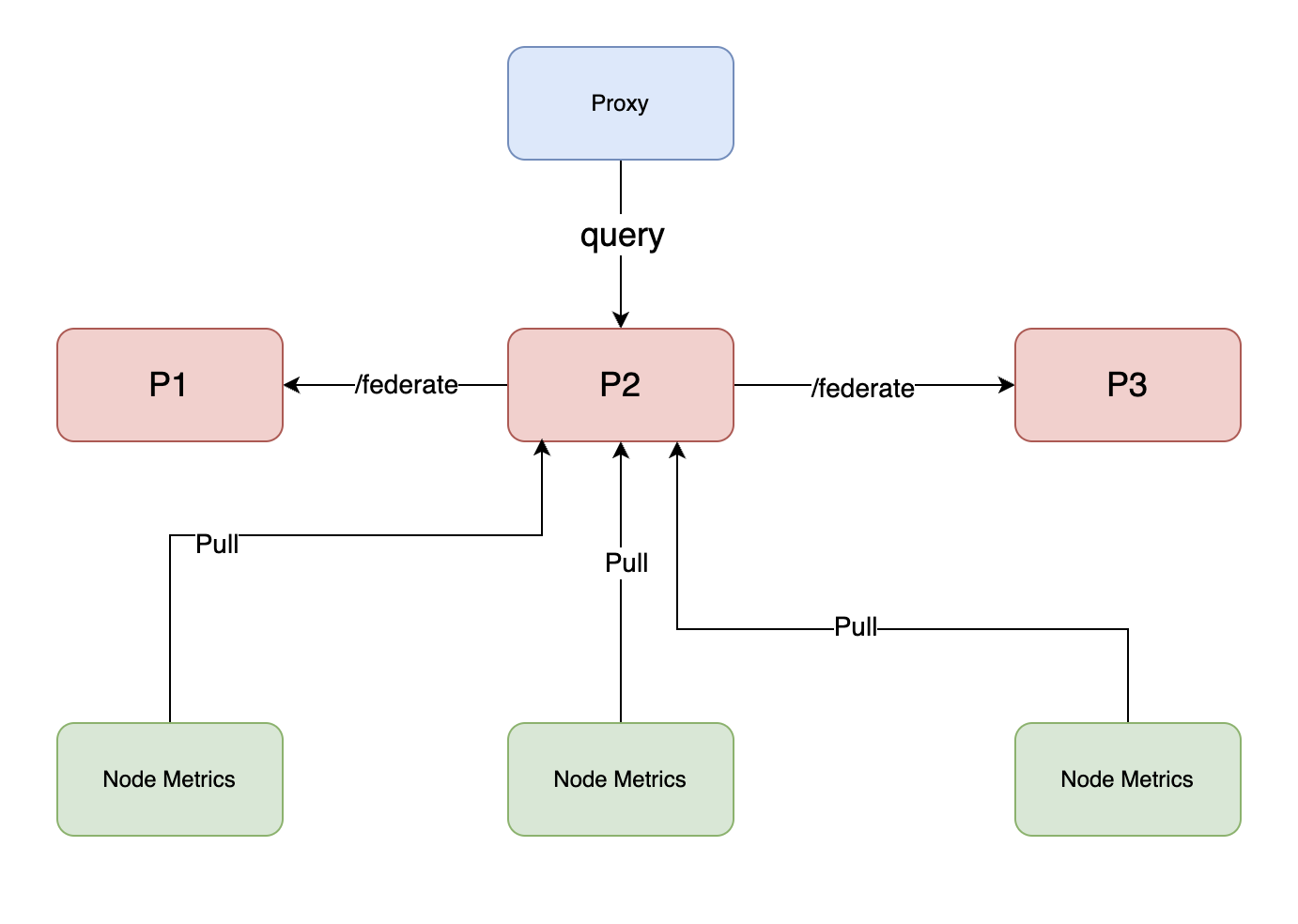
- 优点:a.官方现有方案,配置相对简单;b.数据丢失范围相对可控,数据拉取间隔也是最大可能数据丢失间隔,比如从节点每隔10s拉一次cpu指标数据,那么从节点最大可能丢失10s的cpu指标数据;
- 缺点:a.无法拉取历史数据;b.一致性问题,主从同步延迟,查询从节点的监控数据会存在延迟;c.一主多从时候,对主节点的网络IO压力加大,但压缩传输消耗很小,很难达到瓶颈。
五、选主和配置热重载
- 基于etcd的分布式锁选主
3台prometheus的选主逻辑:主节点获得etcd的分布式锁,间隔30s租约续租方式保活,超过30s不续租,则会触发重新选主。支持手动选主,手动选主的方式是,在主节点续租的时候判定是否存在手动设置的主节点并且在选主的时候判定是否存在手动设置的主节点。

- 配置热重载
a.官方支持的 curl -X POST http://IP/-/reload,或者kill -HUP pid,会自动重新读取配置文件prometheus.yml;
优点:不用改造源码,方便后续prometheus升级; 缺点:需要程序操作生成yml配置文件并访问节点触发配置更新;
b.改造源码prometheus.Config.reloadConfig,实现基于ETCD的配置热重载,比如watch ETCD key并获取配置热重载。
优点:不需要admin程序直接访问prometheus节点,通过etcd解耦配置加载和写入; 缺点:改造源码后对后续升级不太友好,并且需要较多开发和测试成本投入;
六、相关疑问
- 磁盘限制
Prometheus中存储的每一个样本大概占用1-2字节大小 磁盘大小 = 保留时间 * 每秒获取样本数 * 样本大小 2byte * 1 * (36002415) = 2.5GB 假设每秒钟采集cpu占用指标,并且保存数据1个月,消耗的磁盘是2.5GB
storage.tsdb.path 存储数据的目录,默认为data/ storage.tsdb.retention.time 数据过期清理时间,默认保存15天
单节点存储的限制,无法持久化海量的metrics数据,数据持久化的问题,默认保存15天 原生的TSDB对于大数据量的保存及查询支持不太友好 所以并不适用于保存长期的大量数据(只能使用其他远程存储解决)一般Prometheus推荐只保留几周或者几个月的数据;
- 单机prometheus采集指标数量大了会影响性能吗
一主的情况下,如果大量的target需要采集,prometheus pull的数据太多会带来以下几个问题: 1.带宽占用 2.内存 3.CPU
官方推荐的是做分片,比如ABC三台prometheus分别采集不同业务的Metrics 最后有一个C prometheus通过联邦机制汇总所有监控数据用于查询
但是关于带宽,prometheus的1个指标大概就 10bytes 例如:
TYPE app_system_request counter app_system_request 0
- federate机制主从最大可能丢失的数据范围是多大
取决于拉取数据的间隔,间隔15s的话,如果主节点宕机,那么会丢失主节点15s以内的监控数据。
- federate的拉取间隔会如何影响指标数据展示
假设federate的更新时间点是10s一次,而job=cpu的监控要求是2s一次,意味着从节点监控数据查询的话没办法实现高频率 (2s) 更新cpu指标监测但可以针对不同的指标设置不同的采集频率,或将所有的查询请求打到主节点.
- 单机的prometheus数据存储是多久
Prometheus TSDB (Time Series DataBase) 以时间线分块存储监控数据。Prometheus的本地存储默认保留15天的数据,之后就会删除旧数据,间隔可以通过修改配置文件中的参数进行自定义。
- 主节点离线后再次接入监控集群,注册节点到选主再到切主成功大概需要多久
主节点离线,租约10s续约一次,假设主节点刚刚续约完就宕机了,那么在10s租约内,无法切主;过了10s之后,从节点获得分布式锁,选主成功,之后触发配置更新和热重载。
- etcd宕机了,prometheus的运行情况是什么样的
如果是主节点正常的情况下,从节点和主节点工作正常;如果主节点不正常的情况下,从节点无法从主节点拉取数据,同时无法依赖etcd重新选主,从节点无法拉取指标;
- 采集指标带宽占用如何计算
看exporter数量,1个exportner采集目标一个http请求,一个指标大概就2kb
1个指标内容示例如下: HELP app_system_request request counter TYPE app_system_request counter app_system_request 1
- federate会同步历史数据吗
不会,联邦机制同步的是即时向量,走的是即使查询,历史的无法同步,需要手动同步文件系统通常是/data目录
- prometheus的内存消耗如何计算
首先存储结构来看,prometheus将数据按照时间段分块存储 每一块数据单位为Block(Block里面的单位是chunk1、chuck2...和index、meta.json);
内存消耗: 1.因为每隔2小时有一个block数据落盘,落盘之前所有数据都在内存里面(限制block大小、缩短落盘间隔); 2.数据查询时,是从磁盘到内存的,查询范围越大,内存越大;
内存消耗大小计算: 假设采集的指标只有1个cpu的,cpu{node=xxx} 只有3个node,每15s采集一次,那么内存占用是2mb;
如何降低内存消耗: 1.优化数据查询不要查询过大的时间范围的数据; 2.调整query timeout(查询超时时间)对于不合理的查询超时后及时回收资源; 3.--storage.tsdb.max-block-duration:该参数用于设置存储周期的最大时间范围,单位为小时。 默认值为 2 小时。可以根据需要适当调整该值,以减少存储需求和内存占用; 4.--storage.tsdb.max-block-size:该参数用于设置每个块的最大大小,单位为字节。 默认值为 512MB。可以根据需要适当调整该值,以减少内存占用; 5.Linux 中可以使用 ulimit 命令限制prometheus内存占用;
- 如何手动干预选主
干预抢ETCD锁和续约过程就可以实现手动选主;
- 如何防止prometheus的内存爆满
- 配置合理的 retention time(数据保存周期)和 storage size(数据保存大小)。这样可以避免 Prometheus 存储过多无用的数据。
- 使用短周期的数据抽样。通过将采样间隔降低到几秒钟,可以大大减少时间序列数据的数量。
- 调整 query timeout(查询超时时间)。如果查询超时,则查询将被取消,从而避免资源的浪费。
- 避免使用复杂的 PromQL 查询语句。复杂查询语句需要更多的计算资源,占用更多的内存。
- 使用Prometheus的remote write功能,将数据推送到外部存储中,释放的内存压力。
- 将Prometheus部署在资源较为充足的机器上,并尽可能提高机器的硬件配置。
- 如何控制prometheus运行内存占用大小
在 Prometheus 配置文件中,可以使用以下参数来设置最大内存占用: --storage.tsdb.max-block-duration:该参数用于设置存储周期的最大时间范围,单位为小时。 默认值为 2 小时。可以根据需要适当调整该值,以减少存储需求和内存占用。 --storage.tsdb.retention:该参数用于设置每个使用者的数据保留时间。默认值为 15 天。 可以根据需要适当调整该值,以减少存储需求和内存占用。 --storage.tsdb.max-block-size:该参数用于设置每个块的最大大小,单位为字节。 默认值为 512MB。可以根据需要适当调整该值,以减少内存占用。
另外,还可以通过以下参数来配置 Prometheus 进程的最大内存占用: --storage.tsdb.no-lockfile:该参数用于禁用锁定文件,以减少磁盘 I/O。 在高负载环境中使用该参数可能会导致内存占用增加,但可以提高性能。 --storage.tsdb.wal-compression:该参数用于启用 WAL 压缩,以减少磁盘 I/O 和内存占用。 默认情况下,WAL 压缩是禁用的。可以根据需要启用该功能。 最后,还可以使用操作系统的资源限制功能来限制 Prometheus 进程的最大内存占用。 例如,在 Linux 中可以使用 ulimit 命令来设置进程的最大虚拟内存或物理内存限制。
- prometheus版本升级和编译
$ go build ./cmd/prometheus- storage.local.memory-chunks作用
Prometheus的storage.local.memory-chunks是一个配置参数, 用于调整Prometheus本地存储的内存占用量,控制Prometheus在内存中保留的时间序列数据点数量。
具体来说,memory-chunks参数指定了Prometheus在内存中保留的时间序列数据块的数量。 每个数据块包含一组时间序列数据点,这些数据点按照时间排序,并按照其标记(labels)进行索引。 为了支持快速查询和聚合操作,Prometheus需要将一些时间序列数据点保留在内存中。 memory-chunks参数的值越高,Prometheus在内存中保留的时间序列数据点就越多,但同时也会占用更多的内存资源。
通过调整memory-chunks参数,用户可以平衡Prometheus在内存占用和查询性能之间的权衡。 如果Prometheus需要处理大量的时间序列数据点,可以增加memory-chunks的值,以提高查询性能。 但同时也需要确保Prometheus有足够的内存资源来存储这些数据点。
- prometheus federation 和 remote write有哪些缺点
Prometheus Federation 缺点:
- 需要手动配置和管理,对于大规模集群可能会增加管理成本。
- Federation 中的实例依赖于网络性能,如果网络延迟较高,则可能导致数据同步不及时。
- 不支持查询跨越多个 Federation 实例的聚合查询。
虽然也是即时向量查询 - 但是这个查询回溯间隔可以设置大一点比如设置query.lookback-delta=5m,那么可以查到倒计时5min内最后的指标cpu{node=xxx}@1232134324 56
Remote Write 缺点:
- 需要对写入的数据进行格式化和编码,使其适用于远程写入的目标存储系统。
- 如果目标存储系统宕机或出现故障,数据可能会丢失或无法恢复。
- Remote Write 操作需要进行网络传输,可能存在网络延迟等问题,可能导致数据同步不及时。
- 是否可以remote write prometheus
感觉这个特点很多人不知道 以为 remote read\remote write 必须配置第三方存储如 m3db 等, 其实目标也可以prometheus实例 只不过需要开启 --enable-feature=remote-write-receiver
- query.lookback-delta参数作用
即时查询(Instant Query) 返回的内容叫做即时向量( Instant Vector) 因为是即时,如果当时没有数据,它会往前追溯,找到一个时间点。 这个往回追溯的参数的值由 Prometheus 的启动参数 --query.lookback-delta 控制 这个参数默认是 5 分钟。从监控的角度来看,建议调短一些 比如改成 1 分钟 --query.lookback-delta=1m
- 范围查询(Range Query)写法
范围查询(Range Query),返回的内容叫做 Range Vector {__name__=~"node_load.*", zone="sh"}[1m] 这个范围就是1分钟,采集的多少个点都会返回.
- 本地启动如何指定存储路径
# 数据存储在目录 /Users/Documents/data
$ ./prometheus --storage.tsdb.path=/Users/Documents/data \
--config.file=/Users/Documents/prometheus.yml \
--web.listen-address=:8989