alertmanager
大约 16 分钟
使用docker和自定义指标搭建promethus服务、alertmanager服务,试用邮件告警功能
一、启动alertmanager
- 配置
$ mkdir -p /Users/xuweiqiang/Documents/alertmanager/
$ mkdir -p /Users/xuweiqiang/Documents/alertmanager/template
$ touch /Users/xuweiqiang/Documents/alertmanager/config.yml
$ touch /Users/xuweiqiang/Documents/alertmanager/template/email.tmpl
$ cd /Users/xuweiqiang/Documents/alertmanager$ vim /Users/xuweiqiang/Documents/alertmanager/alertmanager.yml
$ touch /Users/xuweiqiang/Documents/alertmanager/template/email.tmpl# config.yml
global:
resolve_timeout: 5m
smtp_from: '435861851@qq.com' # 发件人
smtp_smarthost: 'smtp.qq.com:587' # 邮箱服务器的 POP3/SMTP 主机配置 smtp.qq.com 端口为 465 或 587
smtp_auth_username: '435861851@qq.com' # 用户名
smtp_auth_password: '123' # 授权码
smtp_require_tls: true
smtp_hello: 'qq.com'
templates:
- '/etc/alertmanager/template/*.tmpl'
route:
group_by: ['alertname'] # 告警分组
group_wait: 5s # 在组内等待所配置的时间,如果同组内,5 秒内出现相同报警,在一个组内出现。
group_interval: 5m # 如果组内内容不变化,合并为一条警报信息,5 分钟后发送。
repeat_interval: 5m # 发送告警间隔时间 s/m/h,如果指定时间内没有修复,则重新发送告警
receiver: 'email' # 优先使用 wechat 发送
routes: #子路由,使用 email 发送
- receiver: email
match_re:
serverity: email
receivers:
- name: 'email'
email_configs:
- to: '435861851@qq.com' # 如果想发送多个人就以 ',' 做分割
send_resolved: true
html: '{{ template "email.html" . }}' #使用自定义的模板发送<!-- 配置告警模板 -->
{{ define "email.html" }}
{{ range $i, $alert :=.Alerts }}
========监控报警==========<br>
告警状态:{{ .Status }}<br>
告警级别:{{ $alert.Labels.severity }}<br>
告警类型:{{ $alert.Labels.alertname }}<br>
告警应用:{{ $alert.Annotations.summary }}<br>
告警主机:{{ $alert.Labels.instance }}<br>
告警详情:{{ $alert.Annotations.description }}<br>
触发阀值:{{ $alert.Annotations.value }}<br>
告警时间:{{ $alert.StartsAt.Format "2006-01-02 15:04:05" }}<br>
========end=============<br>
{{ end }}
{{ end }}- 启动alertmanager
$ docker run -d \
--network p_net \
--network-alias alert \
--name=alertmanager \
-p 9093:9093 \
-v /Users/xuweiqiang/Documents/alertmanager:/etc/alertmanager \
prom/alertmanager:latest二、启动prometheus
- 配置
$ touch /Users/xuweiqiang/Documents/alertmanager/prometheus.yml
$ mkdir -p /Users/xuweiqiang/Documents/alertmanager/rules
$ touch /Users/xuweiqiang/Documents/alertmanager/rules/one.yml# prometheus.yml
global:
scrape_interval: 5s
evaluation_interval: 5s
# 配置告警服务端点Endpoints
alerting:
alertmanagers:
- static_configs:
- targets:
- alert:9093
# 配置指标采集目标
scrape_configs:
- job_name: "request_count"
metrics_path: '/metrics'
static_configs:
- targets: ["docker.for.mac.host.internal:6969"]
rule_files:
- "/etc/prometheus/rules/*.yml"# 在Prometheus配置告警规则确定什么样的情况下需要发送告警信息
# rules/one.yml
groups:
- name: hostStatsAlert
rules:
# CPU使用大于85的时候
- alert: hostCpuUsageAlert
expr: (1 - avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance))*100 > 85
for: 1m
labels:
severity: critical
annotations:
summary: "Instance {{ $labels.instance }} CPU usage high"
description: "{{ $labels.instance }} CPU usage above 85% (current value: {{ $value }})"
# 内存使用大于70%的时候
- alert: hostMemUsageAlert
expr: (1 - (node_memory_MemAvailable_bytes{} / (node_memory_MemTotal_bytes{})))* 100 > 70
for: 1m
labels:
severity: critical
annotations:
summary: "Instance {{ $labels.instance }} MEM usage high"
description: "{{ $labels.instance }} MEM usage above 70% (current value: {{ $value }})"
# 1min以内请求次数大于3次的时候就发送告警
- alert: request_counter
expr: app_system_request > 3
for: 1m
labels:
severity: critical
annotations:
summary: "Instance {{ $labels.instance }} request count too much"
description: "{{ $labels.instance }} request count above 3 (current value: {{ $value }})"- 启动prometheus
$ docker run \
--name alert_client \
-d \
-p 9090:9090 \
--network p_net \
--network-alias alert_client \
-v /Users/xuweiqiang/Documents/alertmanager:/etc/prometheus/ \
prom/prometheus \
--config.file=/etc/prometheus/prometheus.yml三、模拟告警指标
四、如何对Alertmanager历史告警存档
1.webhook程序自定义持久化
结论: alertmanager没有本地存储(持久化通过webhook适配)
- alertsnitch + MySQL
- alertmanager-webhook-logger
2.alertmanager提供的http api
// alerts获取告警信息返回内容
// 源代码地址 /code/alertmanager/api/v1/api.go
// 依赖的api对象仅仅存储内存之中重启就丢失了这些告警信息了
[
{
"annotations":{
"description":"localhost:6969 request count above 3 (current value: 9)",
"summary":"Instance localhost:6969 request count too much"
},
"endsAt":"2023-04-13T03:12:23.643Z",
"fingerprint":"33beb4a34b645d5c",
"receivers":[
{
"name":"email"
}
],
"startsAt":"2023-04-13T03:08:23.643Z",
"status":{
"inhibitedBy":[
],
"silencedBy":[
],
"state":"active"
},
"updatedAt":"2023-04-13T03:08:26.484Z",
"generatorURL":"http://xxx.tab=1",
"labels":{
"alertname":"request_counter",
"instance":"docker.for.mac.host.internal:6969",
"job":"request_count",
"severity":"critical"
}
}
]receivers:
# webhook配置
- name: 'web.hook'
# 实现的webhook程序配置
webhook_configs:
- url: 'http://127.0.0.1:9111/alertmanager/hook'五、prometheus的httpAPI
- alertmanager 的http api接口
- alertmanager 的http api接口描述文档
- http://localhost:9093/api/v2/alerts
- prometheus官方手册querying/api
GET /api/v1/query
POST /api/v1/query
GET /api/v1/query_range
POST /api/v1/query_range六、alertmanager高可用机制
alertmanager使用Gossip机制来解决消息在多台Alertmanager之间的传递问题,使用docker搭建集群验证告警滤重功能
1.官方推荐的高可用架构
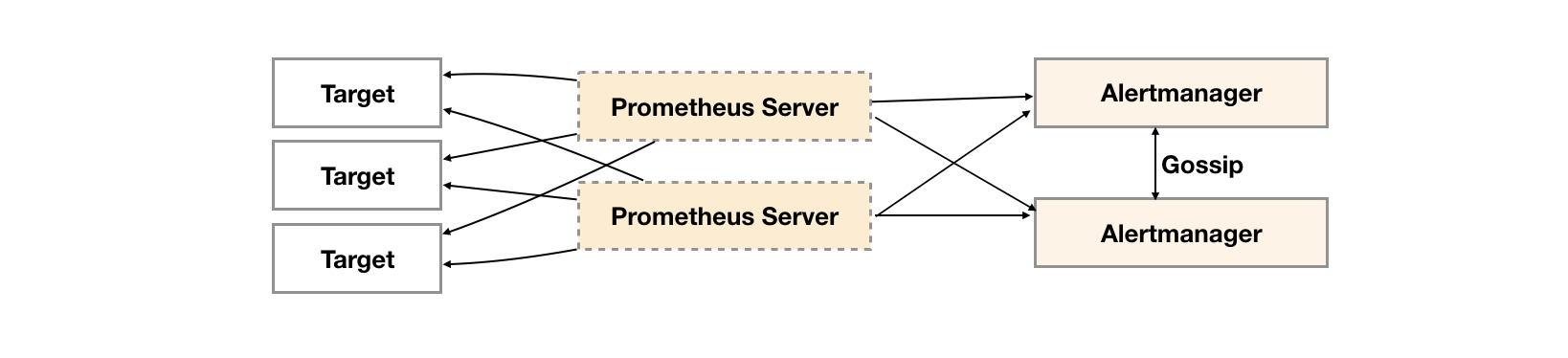
2.如何保证消息不重复
Alertmanager使用Gossip机制来解决消息在多台Alertmanager之间的传递问题。
通过在Alertmanager之间相互交流,将信息同步到所有Alertmanager的方式来避免重复发送给receiver
# 告警流程
1. 当一台Alertmanager接收到告警信息后,它会将这个信息广播给其他Alertmanager;
2. 其他Alertmanager也会将这个信息广播给其他Alertmanager,直到所有Alertmanager都收到了这个信息;
3. 其中只有一台Alertmanager会将这个告警通知发送给接收者;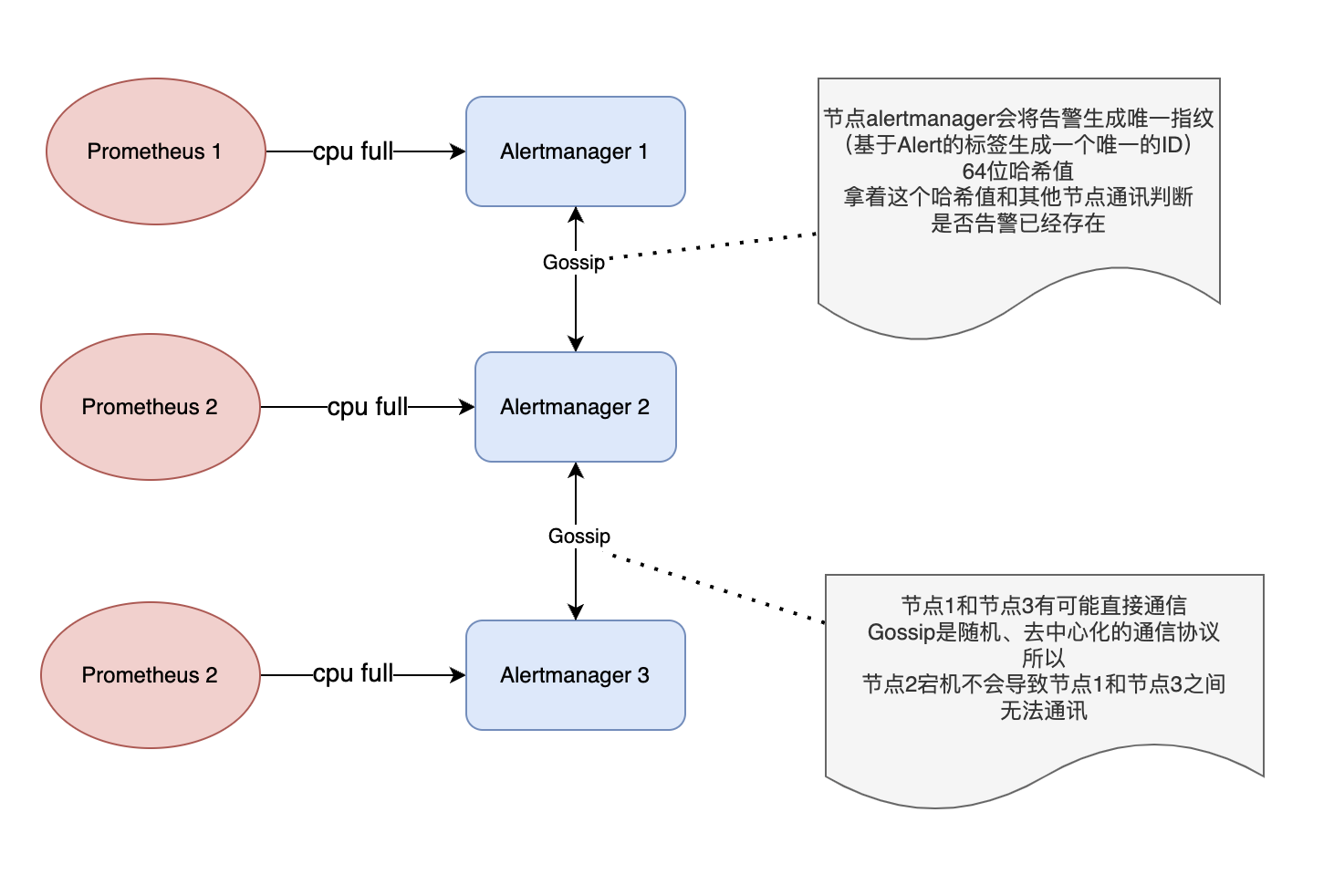
3.Gossip协议
一种去中心化的信息传播协议
# 基本思想是
将消息从一个节点向其他节点随机传播,直到所有节点都收到了该消息,从而实现整个网络范围内的消息传递
任意节点是对等的,无固定中心节点(去中心化、高可用性、可扩展性)
# 应用场景
Gossip 协议可以应用于分布式数据库复制、分布式存储系统、大规模传感器网络等场景中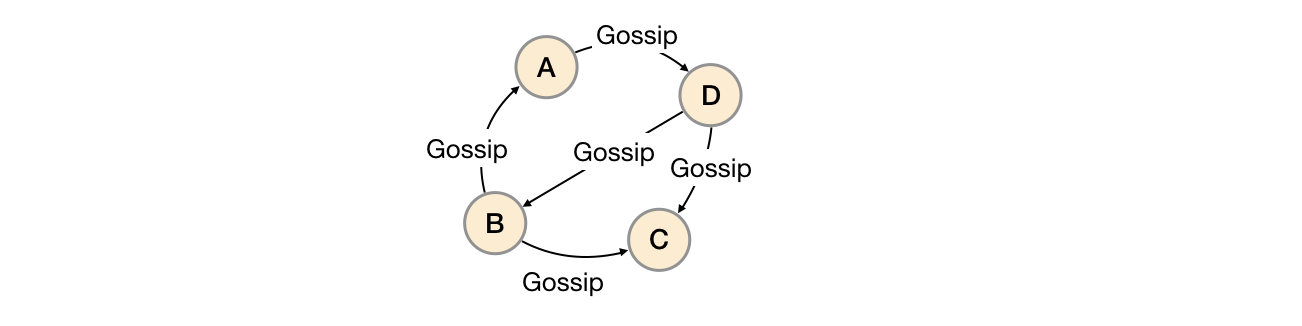
4.协议在Alertmanager的应用场景
# Slience
Alertmanager启动阶段基于Pull-based从集群其它节点同步Silence状态
新的Silence产生时使用Push-based方式在集群中传播Gossip信息
# 告警通知发送完
Push-based同步告警发送状态
# 集群alertmanager成员变化
成员发现、故障检测和成员列表更新等,简而言之,每个alertmanager都知道所有的alertmanager的存在5.Alertmanager如何基于Gossip实现告警不重复的
- 首先,Alertmanager节点之间通过Gossip协议建立相互联系。每个Alertmanager节点都会维护一个Gossip池,用于存储其他节点的状态信息。
- 当集群之中某一个Alertmanager节点接到告警时,首先会计算该告警的Fingerprint(即告警内容的摘要),并将其作为ID使用。
- 然后Alertmanager将该告警的Fingerprint广播给其他Alertmanager节点。
- 接收到广播的Alertmanager会将该Fingerprint添加到自己的已知Fingerprint列表中。
- 当Alertmanager要发送一个告警通知时,会检查该告警的Fingerprint是否已经存在于已知Fingerprint列表中。如果已经存在,则不会发送该告警通知。
也就是说每一个alertmanager节点都拥有所有的告警的Fingerprint,这个Fingerprint列表就是抑制重复发送的ID
6.Alertmanager的Gossip协议有哪些特点
- 高效:Gossip协议使用随机化的节点选择和增量式的消息传递方式,能够在短时间内将信息传递给集群中的所有节点。
- 可靠:Gossip协议采用反馈机制和故障检测算法,能够检测并快速恢复集群中的故障节点,保证集群的稳定性和可靠性。
- 去中心化:Gossip协议不依赖于任何中心节点或集中式控制器,所有节点都是平等的,能够自组织、自平衡和自适应。
7.Alertmanager的集群缺点
1. 增加了复杂性:Alertmanager集群需要进行配置和管理,增加了系统复杂性。
2. 需要更多的资源:Alertmanager集群需要更多的资源,包括计算、存储和网络等。
3. 需要进行监控和日志管理:Alertmanager集群需要进行监控和日志管理,以便及时发现和解决问题。
5. 信息安全性:Alertmanager集群需要注意安全性,尤其是在跨网络或公共网络上运行时。8.什么情况下告警仍然重复发送
1. 集群中的某些节点出现网络故障(比如节点1和节点2同时接收到同一个告警,但是节点1和节点2之间无法通讯)9.两台alertmanager同时接收到告警不会各自立刻发送给receiver导致重复发送吗
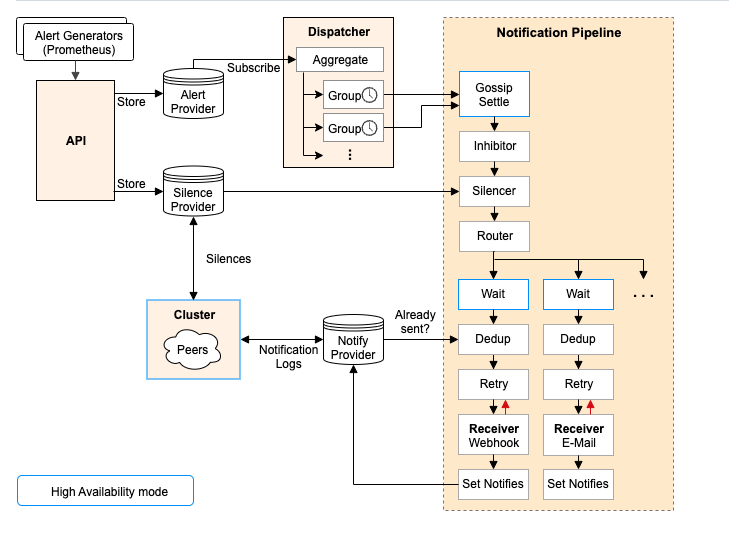
当一个Alertmanager实例将告警通知发送给Receiver时,它会将该通知标记为“暂停发送”,同时向其他实例发送消息,告诉它们“我已经发送了这个告警通知,你们不用再发送了”。这种方式可以确保告警通知在多个实例之间被正确地合并,避免重复发送。剩余多个Alertmanager实例同时接收到相同的告警信息,并且它们之间的通信还没有完成,那么它们都会标记该告警信息为“暂停发送”,并在通信完成之后再决定由哪个实例发送该告警通知。因此,在Alertmanager中,重复发送同一告警通知的情况应该是非常少见的。
10.docker搭建alertmanager集群
# 集群模式下 alertmanager 绑定的 IP 地址和端口号
# 用于与其他 alertmanager 节点进行通信。
# 通过 cluster.listen-address 监听并接收来自其他 alertmanager 节点的请求,并将自己的状态信息同步给其他节点
cluster.listen-address
# alertmanager的cluster.peer是指alertmanager节点在集群中的对等节点
# 用于配置alertmanager的高可用性,确保即使某个节点出现问题,其他节点也能够继续工作
# 当alertmanager节点加入到集群中时,它会将自己的peer信息发送给其他节点,其他节点也会将自己的peer信息发送给它
# 这样,每个alertmanager节点就可以知道其他节点的状态,并在需要时进行切换和故障转移。
#
# 实例的cluster.peer参数,以指定其对等节点的地址
cluster.peer# 创建alertmanager的配置
# 接收到告警之后甩给webhook
$ touch /Users/xuweiqiang/Desktop/a1.yml
$ touch /Users/xuweiqiang/Desktop/a2.yml
$ touch /Users/xuweiqiang/Desktop/a3.yml# 配置alertmanager向webhook发送告警信息
route:
receiver: 'default-receiver'
receivers:
- name: default-receiver
webhook_configs:
- url: 'http://docker.for.mac.host.internal:5001/'# a1
$ docker run -d \
--network p_net \
--network-alias a1 \
--name=a1 \
-p 9093:9093 \
-v /Users/xuweiqiang/Desktop/a1.yml:/etc/alertmanager/config.yml \
prom/alertmanager:latest \
--web.listen-address=":9093" \
--cluster.listen-address=":8001" \
--config.file=/etc/alertmanager/config.yml \
--log.level=debughttp://localhost:9093/#/status
# a2
$ docker run -d \
--network p_net \
--network-alias a2 \
--name=a2 \
-p 9094:9094 \
-v /Users/xuweiqiang/Desktop/a2.yml:/etc/alertmanager/config.yml \
prom/alertmanager:latest \
--web.listen-address=":9094" \
--cluster.listen-address=":8001" \
--cluster.peer=a1:8001 \
--config.file=/etc/alertmanager/config.yml \
--log.level=debughttp://localhost:9094/#/status
# a3
$ docker run -d \
--network p_net \
--network-alias a3 \
--name=a3 \
-p 9095:9095 \
-v /Users/xuweiqiang/Desktop/a3.yml:/etc/alertmanager/config.yml \
prom/alertmanager:latest \
--web.listen-address=":9095" \
--cluster.listen-address=":8001" \
--cluster.peer=a1:8001 \
--config.file=/etc/alertmanager/config.yml \
--log.level=debughttp://localhost:9095/#/status
# webhook
$ go install github.com/prometheus/alertmanager/examples/webhook
# 启动服务
$ webhook11.测试发送告警
alerts1='[
{
"labels": {
"alertname": "DiskRunningFull",
"instance": "example1"
},
"annotations": {
"info": "The disk sdb1 is running full",
"summary": "please check the instance example1"
}
}
]'
curl -XPOST -d"$alerts1" http://localhost:9093/api/v1/alerts
curl -XPOST -d"$alerts1" http://localhost:9094/api/v1/alerts
curl -XPOST -d"$alerts1" http://localhost:9095/api/v1/alerts12.prometheus配置
# 总的一句话就是:每个prometheus往alertmanager集群的所有机器发送告警
# 最大限度保证告警消息不会丢失就好了
alerting:
alertmanagers:
- static_configs:
- targets:
- 127.0.0.1:9093
- 127.0.0.1:9094
- 127.0.0.1:909513.指纹算法
// provides a hash-capable representation of a Metric.
model.Fingerprint uint64
// Fingerprint returns a Metric's Fingerprint.
// 生成指纹算法
type func (m Metric) Fingerprint() Fingerprint
// Equal compares the metrics.
// 指标比对逻辑
func (m Metric) Equal(o Metric) boolAlertmanager的高可用架构是:
- 多台实例之间启用集群通讯模式;
- prometheus各自向自己宿主机的alertmanager实例发送告警信息;
- 使用alertmanager路由将不同的告警(标签区分)发给不同的接受者;
- 使用alertmanager分组将告警合并;
- alertmanager自带的Firing有降噪作用
七、webhook实现
1.golang-webhook
编写简单的webhook程序验证alertmanager告警服务
package main
import (
"encoding/json"
"github.com/prometheus/alertmanager/template"
"log"
"net/http"
)
func main() {
http.HandleFunc("/hook", ServeHTTP)
_ = http.ListenAndServe(":7979", nil)
}
func ServeHTTP(w http.ResponseWriter, r *http.Request) {
var alerts template.Data
err := json.NewDecoder(r.Body).Decode(&alerts)
if err != nil {
http.Error(w, err.Error(), http.StatusBadRequest)
return
}
alertsBytes, err := json.Marshal(alerts)
if err != nil {
http.Error(w, err.Error(), http.StatusBadRequest)
return
}
log.Println(string(alertsBytes))
w.WriteHeader(http.StatusNoContent)
}2.alertmanager配置
$ touch /Users/xuweiqiang/Desktop/alert.ymlglobal:
resolve_timeout: 5s
route:
group_by: ['alertname'] # 告警分组
group_wait: 2s
group_interval: 2s
repeat_interval: 2s
receiver: 'my_webhook'
receivers:
- name: 'my_webhook'
webhook_configs:
- url: 'http://docker.for.mac.host.internal:7979/hook'3.启动alertmanager
$ docker run -d \
--name=hook_alert \
-p 9095:9095 \
-v /Users/xuweiqiang/Desktop/alert.yml:/etc/alertmanager/config.yml \
prom/alertmanager:latest \
--web.listen-address=":9095" \
--config.file=/etc/alertmanager/config.yml \
--log.level=debug4.发送告警
alerts1='[
{
"labels": {
"alertname": "DiskRunningFull",
"instance": "node one"
},
"annotations": {
"info": "disk full",
"summary": "please check disk"
}
}
]'
curl -XPOST -d"$alerts1" http://localhost:9095/api/v1/alerts相关疑问
- 告警状态有哪些
Inactive:这里什么都没有发生。
Pending:已触发阈值,但未知足告警持续时间(即rule中的for字段)
Firing:已触发阈值且满足告警持续时间。警报发送到Notification Pipeline
通过处理,目的是屡次判断失败才发告警,减小邮件- prometheus告警机制如何降噪的
# 简要描述:
Prometheus会根据rules中的规则,不断的评估是否需要发出告警信息,
如果满足规则中的条件,则会向alertmanagers中配置的地址发送告警
告警是通过alertmanager配置的地址post告警,比如targets: [node1:8090']
则会向node1:8090/api/v2/alerts发送告警信息
# 如何验证:
自己实现alertmanger程序,来接收Prometheus发送的告警,并将告警打印出来
# 告警间隔
[prometheus.yml] > global.evaluation_interval = 15s (告警周期)
[rules.yml] > groups[].rules[].for = 1m (具体某一条告警规则的告警时长)
1m 15s就是prometheus推送告警信息的间隔
# 如何理解
1m 是prometheus拉取指标的间隔 (隔1m拉指标1次)
15s是对应的告警设置的持续时间(需要持续15s以上才会告警)
所以第一次pull到异常时候,到第二次再次pull到异常才满足了15s持续的条件
如果设置为0则立刻告警- alertmanager处理告警信息有哪些重要机制
- 路由: 不同的告警来源发给不同的收件人
- 分组: 相同的告警类型合并为一封告警
- 什么情况下会有Firing状态值
Firing状态值通常在Prometheus规则中定义的触发条件成立时出现。
也就是说,当监控指标满足预设的规则条件时,Prometheus会发出告警
并将告警状态设置为Firing,以通知用户进行相应的处理。
常见的情况包括CPU使用率过高、内存使用率超标、网络延迟过高等问题。
这个状态值的意义在于,当你的机器一直处于cpu爆满或其他某一个状态值的时候
不会每隔一段时间发送告警,相当于降噪- 告警路由是什么
route:
receiver: admin-receiver
routes:
- receiver: database-receiver
match:
component: database
- receiver: memcache-receiver
macth:
componnet: memcache以上的路由达到的效果是:
告警的标签匹配 component=database 的发送告警给 database-receiver- 分组是什么
route:
receiver: admin-receiver
group_by: ["instance"]
group_wait: 30s
group_interval: 5m
repeat_interval: 4h当alertmanager在一分钟内收到6封告警
其中3封邮件是instance=A
领完3封邮件是instance=B
并且group wait为1分钟以上
在group wait期间收到的这6封告警
会合并为2封告警信息对于告警
{alertname="NodeCPU",instance="peng01",...}
会创建分组
{instance="peng01"}
那么同一个组的告警,将会等待group_wait的时间,alertManager会把这一组告警一次性发给Receiver
假设group_interval为5分钟,意思是,同一个组的告警,在发送了告警之后,这个时间间隔内,不会再次发送告警
但是超过了这个时间(5min),有同一个组的告警到达,会在等待group_wait时间后立刻发送告警- 主从多台alertmanager之下如何滤重告警
Gossip协议下的集群- alertmanager接收到告警之后处理流程怎么样的
1. 某个Alertmanager接收到告警,会等待一段时间(默认为30秒)看其他Alertmanager节点是否接到该告警
2. 等待聚合时间结束后,Alertmanager集群仍然没有收到该告警的聚合,则它将发送给接收器(receiver)
等待时间称为“等待聚合”(wait_for_aggregate)时间,可以在Alertmanager配置文件的route部分进行配置;- prometheus的alert有多少种状态
- Unfiring:告警规则触发,但没有达到告警阈值,未达到告警状态。
- Firing:告警规则触发,已达到告警阈值,处于告警状态。
- Pending:正在等待确认,已发送告警通知但还未确认。
- Silenced:已被静默,告警规则被设置为不产生告警。
- Inhibited:已被禁止,告警规则被设置为禁用告警。
- Alertmanager的Webhook是什么
Alertmanager的Webhook是一种机制,可以通过向指定URL发送HTTP、POST请求来将警报发送到外部系统。
Webhook可用于将警报通知转发到其他应用程序、服务或系统,或将其集成到自动化工作流程中。
使用Webhook,可以将警报发送到任何支持HTTP接口的服务或应用程序。package main
import (
"time"
"io/ioutil"
"net/http"
"fmt"
)
type MyHandler struct{}
func (am *MyHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
body, err := ioutil.ReadAll(r.Body)
if err != nil {
fmt.Printf("read body err, %v\n", err)
return
}
fmt.Println(time.Now())
fmt.Printf("%s\n\n", string(body))
}
func main() {
http.Handle("/webhook", &MyHandler{})
http.ListenAndServe(":10000", nil)
}- alertmanager如何查看历史告警
Alertmanager提供了HTTP API,可以通过该API来查询历史告警。
具体来讲,可以通过以下API来获取历史告警:
1. /api/v1/alerts:该API可以用来查询当前和历史告警。
默认情况下,该API只查询当前处于pending、firing或者silenced状态的告警。
为了查询历史告警,需要在请求参数中添加start和end参数,指定查询的时间范围。
2. /api/v1/alerts/groups:该API可以用来查询当前和历史告警的分组信息。
类似于上面的API,需要在请求参数中添加start和end参数来指定查询的时间范围。
3. /api/v1/alerts/<alertname>/<instance>:该API可以用来查询指定告警名称和实例的历史告警。
类似于上面的API,需要在请求参数中添加start和end参数来指定查询的时间范围。
需要注意的是,默认情况下,Alertmanager只会保留最近2小时的历史告警。
如果要查询更早期的历史告警,需要对Alertmanager进行配置
将history配置项设置为一个大于0的值,以指定历史告警的保留时间。- 对于proemtheus的联邦机制而言,是否会因为标签不一致导致重复发送呢
取决于备用节点从主节点拉取指标的时候是否保留原有标签(honor_labels:true)
更改标签会导致生成的指纹不一致导致重复发送告警参考资料
- csdn.net之Prometheus一条告警是怎么触发的
- cnblogs.com之Prometheus发送告警机制
- zhuanlan.zhihu.com开箱即用的 Prometheus 告警规则集
- cloud.tencent.com使用Docker部署alertmanager并配置prometheus告警
- pshizhsysu.gitbook.io告警的路由与分组
- Alertmanager告警全方位讲解
- 基于Alertmanager设计告警降噪系统-转转
- webhook-receiver.go
- 官方webhook reveiver集成写法
- 查看webhook标准写法
- Alertsnitch: saves alerts to a MySQL database
- rate 和 irate 函数解析
- Alertmanager高可用
- https://github.com/prometheus/alertmanager
- webhook的数据标准是什么
- 官方手册alerting/configuration/#webhook_config
- 官方推荐webhook实现